Réduire l’impact des ruptures de stock avec une prévision agrégée

De nombreuses entreprises n’ont pas de processus d’archivage ou de suivi des ruptures de stock, bien que celles-ci puissent avoir un impact significatif sur les ventes. Cet article explique comment les organisations peuvent minimiser l’effet des ruptures de stock sur la prévision de la demande en utilisant des méthodes de prévision agrégées et des données de ventes réelles. Bien qu’il serait préférable d’utiliser la demande réelle plutôt que les ventes historiques en éliminant les ruptures de stock, notre expérience indique que la plupart des entreprises n’ont pas encore atteint ce stade de maturité dans la gestion de leur supply chain. Essai gratuit – Prévision & Suivi de performanceFacile et Abordable – Aucune carte de crédit requiseEssayer SKU Science maintenant! Obtenez vos prévisions gratuitement Les bénéfices de l’utilisation de données agrégées pour la prévision de la demande Les meilleures pratiques en gestion de supply chain pour atteindre une plus grande précision de la prévision consistent à calculer les prévisions à un niveau agrégé. Voici quelques raisons pour lesquelles les indicateurs clés de performance (KPI) de la prévision de la demande s’améliorent généralement avec cette approche : – Augmentation de la taille de l’échantillon : En agrégeant les données provenant de sources multiples, vous augmentez la taille de l’échantillon de vos données, ce qui peut améliorer la précision de vos prévisions. Une taille d’échantillon plus grande peut fournir une vue plus représentative de la population, permettant des prédictions plus solides et fiables. – Réduction du bruit : L’agrégation des données peut aider à réduire les effets du bruit et des valeurs aberrantes dans les données. Par exemple, si vous prévoyez la demande d’un produit, une demande exceptionnellement élevée d’un seul client ou d’un emplacement particulier peut fausser les données et entraîner une prévision inexacte. En agrégeant les données provenant de plusieurs clients ou emplacements, vous pouvez réduire l’impact de ces valeurs aberrantes et produire des prévisions plus précises. – Meilleure compréhension des motifs sous-jacents : L’agrégation des données peut vous aider à identifier des motifs et des tendances que vous ne pourriez pas voir en travaillant avec des points de données individuels. Par exemple, si vous prévoyez la demande d’un produit dans plusieurs magasins, vous pourriez remarquer que la demande est généralement plus élevée les week-ends ou pendant certains mois de l’année. En identifiant ces motifs, vous pouvez créer des prévisions plus précises. – Plus de puissance explicative : L’agrégation des données peut vous donner une compréhension plus complète des facteurs qui influencent la demande d’un produit ou d’un service. Par exemple, en analysant les données provenant de plusieurs magasins, vous pouvez identifier à la fois un motif saisonnier et des caractéristiques spécifiques à chaque magasin qui affectent la demande. La combinaison de ces deux facteurs peut fournir plus de puissance explicative et des prévisions plus précises. Techniques efficaces de regroupement de données pour une prévision de la demande fiable Maintenant, voyons quel type de données nous pourrions utiliser pour regrouper nos données afin d’appliquer nos modèles de prévision. – Les données de produit telles que la taille, le poids, la couleur, le prix, la marque, le segment, la catégorie ou toute autre information pouvant caractériser un produit peuvent être utilisées pour agréger les données. – Les données de magasin peuvent également être utilisées pour comprendre comment la demande d’un produit varie selon les différents emplacements de magasin. Cela peut inclure des informations telles que la taille du magasin, la disposition et les caractéristiques démographiques de la zone environnante. – Le canal de vente est un autre exemple d’information qui peut être utilisé pour organiser vos données avant de calculer la prévision, car la demande pour des canaux spécifiques peut être très différente. – Les données de marketing telles que les promotions ou les publicités qui ont été réalisées pour le produit peuvent aider à comprendre l’effet de ces activités sur la demande. Par conséquent, le regroupement de données en utilisant ces champs ou une combinaison de ces champs peut conduire à une meilleure précision lors de la prévision de la demande. Cette table montre le taux d′erreur moyen en % pour les prévisions calculées à un niveau d′agrégation spécifique. Améliorer la précision des prévisions de la demande grâce à l’analyse des données agrégées et des ruptures de stock Si les données de vente historiques sont affectées par des ruptures de stock, cela peut entraîner des imprécisions dans les prévisions de la demande, car les ruptures de stock peuvent entraîner des fluctuations des ventes qui ne reflètent pas la véritable demande sous-jacente. Comme nous l’avons vu précédemment, travailler avec des données agrégées peut aider à améliorer la précision des prévisions de la demande dans cette situation pour quelques raisons : – Effet lissage : L’agrégation des données de vente provenant de plusieurs sources peut contribuer à lisser les fluctuations de ventes causées par des ruptures de stock individuelles. Par exemple, si les données de vente d’un magasin sont affectées par une rupture de stock, elles peuvent être compensées par les données de vente d’un autre magasin où les ruptures de stock ne se sont pas produites. – Meilleure compréhension de l’impact des ruptures de stock : En agrégeant des données provenant de plusieurs magasins, vous pouvez également
Challenger les prévisions de vos commerciaux avec le suivi des KPI

Pour améliorer les performances de votre supply chain, il est essentiel d’avoir les bons outils pour accompagner la planification de demande au sein de votre S&OP. Vous pouvez ainsi limiter les ruptures de stock et maintenir votre inventaire à un niveau raisonnable, tout en garantissant un taux de service élevé. Un élément clé de la planification de demande est l’obtention de bonnes prévisions. Bien souvent, ces prévisions proviennent des commerciaux et des distributeurs, cependant la qualité de ces prévisions est fréquemment remise en cause par les personnes en charge de la supply chain. Focus sur les KPI de prévisions des équipes commerciales En pratique, il faut organiser la mesure de la qualité de ces prévisions (les fameux KPI). Mais c’est un exercice difficile à effectuer avec Excel. De plus, on peut écrire sans risque, qu’il y a autant de façons d’évaluer ces prévisions qu’il y a d’entreprises. Nous proposons ci-dessous un tableau de suivi des performances, pour identifier rapidement les articles, ou les niveaux dans l’organisation nécessitant des mesures correctives. SKU Science apporte une solution pour sensibiliser tous les acteurs de la chaîne logistique à l’amélioration des prévisions. Il est possible de recréer ce tableau à la main sous Excel, mais c’est un exercice compliqué et qui demandera une maintenance mensuelle. Plusieurs clients nous ont demandé de pouvoir comparer les prévisions fournies par leurs services commerciaux à celles calculées par notre plateforme.Sur le tableau vous pouvez voir deux types de prévisions. Ainsi tous les KPI sont calculés à la volée pour les 2 deux types de prévisions (en fonction des délais d’approvisionnement de votre supply chain, sinon cela n’a pas vraiment d’intérêt) et comparés entre eux pour calculer la valeur ajoutée de votre équipe commerciale. Mesurer la valeur ajoutée de vos équipes Vos équipes passent du temps à faire des prévisions, mais cela n’a du sens que si elles améliorent vraiment les prévisions issues d’un outil comme SKU Science ou d’une autre plateforme. En comparant ces deux valeurs, vous saurez enfin si vous ajoutez de la valeur ajoutée, ce qui doit être votre seul et unique objectif. Concrètement comment ça se passe?A partir des données historiques de la demande, la plateforme calcule des prévisions pour les derniers cycles. Lors de chaque période, une nouvelle prévision externe a été chargé à partir d’Excel sur la plateforme. Ces prévisions (“Rolling forecast” en anglais) issues de la plateforme et des commerciaux sont archivées à chaque nouveau cycle. Dans l’exemple ci-dessous, nous analysons les données de prévision avec un mois d’écart pour chaque période.Au lieu de nous concentrer sur les prévisions au niveau d’une SKU (vous pouvez en avoir beaucoup), nous étudions les prévisions à un niveau plus macroscopique, celui d’un territoire ou d’un entrepot (ici Paris). Cet exercice est réplicable à n’importe quel niveau. La plateforme nous permet d’obtenir sans effort les tableaux de KPI calculés à partir des quantités ou valorisés financièrement. Dans l’exemple ci-dessous, un tableau de KPI pondérés est généré à partir du chiffre d’affaires de chaque SKU. Cela reste la meilleure option pour analyser les KPI et avoir un réel impact sur la société.Chaque KPI de prévision calculé comporte 3 lignes. • SKU Science: indique les valeurs concernant les prévisions de la plateforme.• Utilisateur: indique les valeurs pour la prévision issue du service commercial et chargée sur la plateforme.• Valeur ajoutée: représente l’amélioration ou la dégradation apportée par l’utilisateur par rapport à SKU Science. Valeur ajoutée des prévisions et KPI pondérés Il est aisé de constater dans ce tableau que la valeur ajoutée de la précision, en rouge, est inférieure de 5% à celle obtenue par la plateforme. Il faut donc prendre des mesures correctives lors des prochains cycles, pour faire passer ce chiffre en positif. Nous donnerons quelques conseils à ce sujet dans un autre article. Sans amélioration lors des prochains cycles, il est préférable de ne rien changer aux prévisions de la plateforme et d’éviter de faire perdre du temps à vos équipes. Une autre information importante que l’on peut extraire de ce tableau est l’écart moyen entre le chiffre d’affaires réalisé pour chaque période et le biais de prévision. Ici on constate grâce au signe négatif, que le service commercial sous évalue en moyenne de 414k€ par mois par rapport au CA réalisé. Sans une bonne politique de stock, les ruptures sont à redouter sur certains articles sur la zone de Paris. Un signe positif traduirait une tendance à la surestimation des quantités, ce qui se traduirait immanquablement par une augmentation de l’inventaire. L’idéal serait d’avoir un biais en pourcentage proche de zero. De manière générale, il est de bonne pratique d’analyser les KPI de prévision par rapport au CA ou par rapport à la marge dégagée par l’entreprise.Pour certains articles clés, il peut être cependant intéressant d’analyser ce tableau sous l’angle des quantités. Essai gratuit – Prévision & Suivi de performanceFacile et Abordable – Aucune carte de crédit requiseEssayer SKU Science maintenant! Obtenez vos prévisions gratuitement
Comment mettre en place un processus de prévision de la demande

Une prévision n’est pertinente que si elle permet de prendre les mesures appropriées pour votre supply chain. Un bon modèle de prévision devrait permettre d’améliorer le niveau de service, de mieux planifier, de réduire le gaspillage et les coûts globaux. Dans cet article, nous présentons les 4 dimensions à considérer pour définir le cadre d’un bon processus de prévision de la demande pour votre organisation. Lors de la création de votre processus de prévision de la demande, vous devrez le définir selon quatre dimensions: la granularité, la temporalité, les métriques et le processus. 1. Granularité Vous devez d’abord travailler à déterminer la bonne granularité géographique et matérielle pour vos prévisions. ?️ Géographique. Devez-vous prévoir par pays, région, marché, canal, segment de clientèle, entrepôt, magasin? ? Matériel. Devez-vous prévoir par produit, segment, marque, valeur, matière première requise? Pour répondre à ces questions, vous devez réfléchir aux décisions prises en fonction de cette prévision, et leurs impacts sur votre supply chain. N’oubliez pas qu’une prévision n’est pertinente que si elle améliore votre supply chain. À titre d’exemple, supposons que vous deviez décider des produits à expédier de votre usine à vos entrepôts régionaux. Dans ce cas, il peut être judicieux d’agréger la demande pour chaque région allouée à un entrepôt et de prévoir la demande directement à ce niveau géographique. Pour prévoir la demande allouée à un entrepôt, il est déconseillé d’utiliser les commandes historiques car elles sont impactées par des contraintes logistiques. Au lieu de cela, vous devez prévoir la demande de l’entrepôt en fonction de ce qui devrait être servi à partir de l’entrepôt s’il n’y avait aucune contrainte (en d’autres termes, prévoir la demande provenant de la région géographique qui devrait être desservie par l’entrepôt). Essai gratuit – Prévision & Suivi de performanceFacile et Abordable – Aucune carte de crédit requiseEssayer SKU Science maintenant! Obtenez vos prévisions gratuitement 2. Temporalité Une fois que vous savez à quel niveau de granularité vous allez travailler, vous devez choisir le bon horizon de prévision et l’agrégation temporelle (intervalle de temps). De nombreuses supply chain s’en tiennent à la prévision de la demande 18 ou 24 mois à l’avance, même si vous devrez peut-être choisir un horizon limité sur lequel vous concentrer. ?️ Agrégation temporelle. Quel intervalle d’agrégation temporelle devez-vous utiliser (jour, semaine, mois, trimestre ou année)? ? Horizon. Combien de périodes devez-vous prévoir (un mois, six mois, deux ans)? Encore une fois, vous devez répondre à ces questions en réfléchissant à ce que vous tentez d’optimiser / réaliser et aux délais impliqués dans ces décisions. Par exemple, supposons que vos fournisseurs (ou usines de production) doivent recevoir des commandes / prévisions mensuelles trois mois à l’avance. Dans ce cas, vous savez que vous devez travailler sur des périodes mensuelles et avec un horizon de 3 mois (M+1 /+2/+ 3). Vous pouvez également sauter M+4 (ou du moins ne pas vous concentrer dessus). Si vous avez besoin d’une prévision pour savoir quelles marchandises expédier de votre entrepôt central à vos entrepôts locaux, vous devez vous concentrer sur un horizon équivalent à votre délai d’approvisionnement interne. ❗ Modèles et horizon de prévision. Les modèles statistiques peuvent facilement produire des prévisions sur un très long horizon (théoriquement infini). Ce n’est pas le cas des modèles de machine learning. Ainsi, vous devrez peut-être vous en tenir à des modèles statistiques pour les prévisions à long terme. 3. Métriques Les professionnels négligent souvent la question des mesures de prévision. Choisir les bonnes métriques pour un processus / modèle de prévision est en fait assez simple et aura des impacts profonds sur les prévisions qui en résultent. En fonction de la métrique sélectionnée, vous pourriez donner trop d’importance aux valeurs aberrantes (le défaut du RMSE) ou risquer une prévision biaisée (le défaut de l’EAM). Voici quelques conseils pour choisir les bonnes métriques de prévision : ❌ Evitez MAPE. De nombreux professionnels utilisent encore MAPE comme mesure de prévision. Il s’agit d’un indicateur très biaisé qui favorisera la sous-prévision. ✅ Combinez les KPI. Choisir une combinaison de KPI (comme l’EAM & le Biais) sera souvent un bon compromis vous permettant de contrôler la précision et le biais tout en évitant la plupart des pièges. ✅ Surveillez l’apparition de biais cohérents. Si un biais cohérent (sur ou sous-prévision) est observé sur un élément, quelque chose ne va probablement pas avec le modèle / processus de prévision. ? Les KPI pondérés. Vous pouvez essayer de pondérer chaque produit (ou SKU) dans le calcul de la métrique globale en fonction de sa rentabilité, de son coût ou de son impact global sur la chaîne d’approvisionnement. L’idée est d’accorder plus d’attention aux SKU qui comptent le plus. Au-delà des calculs, il est important d’aligner les KPI de prévision sur les granularités matérielles et temporelles requises. Par exemple, supposons que vous souhaitiez commander des produits auprès d’un fournisseur étranger avec un délai de 3 mois. Dans ce cas, vous devez mesurer la précision sur un horizon de prévision à mois +1, +2 et +3 – ou mieux encore, calculer l’erreur cumulée sur trois mois – au lieu de simplement regarder la précision obtenue au mois+1. 4. Processus de prévision de la demande Maintenant que vous connaissez votre agrégation matérielle et temporelle, votre horizon et vos métriques, vous pouvez mettre en place un processus. Ce processus doit être défini à travers trois aspects spécifiques. – Les parties prenantes. Qui examinera les prévisions? Apporter différents points de vue à la table de discussion – en utilisant diverses sources d’information – aidera à créer une prévision plus précise. – Périodicité. Quand révisez-vous les prévisions? La mise à jour plus fréquente de vos prévisions peut améliorer leur précision (car vous disposez de données plus récentes). Les mettre à jour trop souvent peut créer le chaos car vous réagissez de manière excessive à aux variations de la demande et consommez trop de ressources pour une valeur ajoutée limitée. – Processus de vérification. Comment examinez-vous les prévisions? Au cœur de tout processus de prévision, il devrait y avoir une
6 conseils pour obtenir des prévisions de demande fiables post-COVID-19

La crise COVID-19 a eu un impact sur tous les modèles de prévision de la demande, quel que soit votre secteur. Selon le type d’articles que vous traitez (demande faible vs forte) ou votre secteur industriel (commerce de détail, alimentation, soins de santé, services publics, logistique, fabrication, etc.), certaines mesures doivent être prises pour planifier (relativement ) avec précision pour les mois à venir. La question est: « Comment devrions-nous traiter les données de demande réelle pour mars, avril et mai 2020? » Demande pendant la COVID-19 et son impact sur le modèle de prévision (modèle Saison & Tendance) Eh bien, comme vous pouvez l’imaginer, il n’y a pas une seule réponse à cette question, mais nous allons essayer ci-dessous de lister toutes les options disponibles. Nous sommes à peu près sûrs qu’une de celles-ci conviendra à votre entreprise. La première option évidente consiste à marquer ces valeurs comme des valeurs aberrantes. Si vous décidez de traiter les données de demande de mars à mai 2020 comme des valeurs aberrantes, vous avez alors plusieurs options pour vos calculs de prévision. • Vous pouvez les supprimer de la fenêtre de prévision. • Vous pouvez implémenter certaines tactiques pour réduire leur poids dans vos modèles de prévision. • Vous pouvez utiliser les données historiques des années précédentes pour remplacer ces périodes particulières, en prenant par exemple une moyenne de 2017 à 2019. • Vous pouvez utiliser les données de prévision de votre modèle pour remplacer ces valeurs particulières. Nous expliquerons bientôt dans un autre article comment obtenir rapidement vos prévisions en utilisant cette méthode avec SKU Science. Une fois votre choix tactique fait – et compte tenu du fait que nous sommes toujours dans un monde VUCA – vous pouvez envisager de permettre à votre base de prévision de s’adapter rapidement aux changements de la demande en augmentant la sensibilité des paramètres de prévision. En traitant les données de demande de T1 et T2 2020, non seulement cela vous aidera à planifier correctement pour le reste de l’année, mais aussi pour les T1 et T2 de 2021. En effet, pour ceux qui ont une demande saisonnière, il est probable que vos modèles de prévision « détecteront » une saisonnalité COVID-19 et prédiront une baisse de la demande de mars à mai 2021. Pour certaines industries, signaler les mois de confinement comme des valeurs aberrantes n’est pas toujours la meilleure option, car ces ventes pourraient représenter un nouveau changement structurel qui devrait persister dans l’avenir – des solutions de vidéoconférence et des téléconsultations médicales viennent à l’esprit. Un autre exemple est une augmentation de la consommation de farine qui pourrait rester à ce niveau plus élevé dans les mois à venir, car la cuisine familiale a pris le dessus sur la restauration rapide et la restauration. Par conséquent, il est important que les prévisionnistes de la demande connaissent leur industrie afin de pouvoir interpréter correctement la demande historique. En bref, signaler la demande récente comme des valeurs aberrantes est contre-productif si vos clients ont maintenant changé leur comportement à long terme en raison de la crise. Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT Une autre tactique pour optimiser vos ventes – tout en optimisant votre fonds de roulement – serait de maintenir de faibles niveaux de stock pour les produits finaux tout en maintenant un bon niveau de matière première et d’en-cours de fabrication pour permettre une montée en cadence rapide de la production, afin de pouvoir réagir si la demande augmente. En conclusion, il n’y a pas de solution miracle pour toutes les entreprises. La demande au cours des 3 derniers mois a été exceptionnelle: il est probable que, dans la plupart des cas, la demande post-COVID-19 sera différente de la demande que nous avons connue au cours des 3 derniers mois. Par conséquent – à l’exception de certaines industries essentielles (commerce électronique et alimentation, etc.) – il serait prudent de modifier les données de demande pour Mars, Avril et même Mai. Si vous utilisez actuellement un algorithme statistique ou une boîte noire, il est peut-être temps de revoir le fonctionnement de votre moteur de prévision pour l’empêcher de réagir de manière excessive à la crise COVID-19.
Comment détecter les valeurs aberrantes pour une meilleure prévision de la demande

La plupart des chaînes d’approvisionnement s’attendent à une certaine variabilité de la demande et, par conséquent, il convient de choisir le bon modèle de prévision, comme on peut le voir dans nos précédents articles. Quelle que soit la nature de cette variance, des facteurs exceptionnels peuvent se produire et nuire gravement à la fiabilité d’un modèle donné. Nous appelons ces données des « valeurs aberrantes ». Ces valeurs aberrantes résultent d’abord d’une demande exceptionnelle, telle que la liquidation de stocks, des arrêts temporaires de production ou des restrictions externes, qui peuvent être dues à des contraintes logistiques ou d’infrastructures rendant temporairement impossible la composition du stock ou l’exécution des commandes des clients. Même si certaines observations de la demande sont réelles, cela ne signifie pas qu’elles ne sont pas exceptionnelles et ne doivent pas être nettoyées. Deuxièmement, il y a aussi des erreurs, qui sont des valeurs aberrantes évidentes. Si vous remarquez ce type d’erreurs ou des problèmes d’encodage, vous devez mettre en œuvre des améliorations de processus afin d’empêcher qu’elles ne se reproduisent. Considérant les effets négatifs que les valeurs aberrantes peuvent avoir sur votre entreprise, il est essentiel de savoir comment les détecter et il existe certaines techniques qui peuvent être utilisées pour résoudre ce problème. Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT Détecter les valeurs aberrantes via la winsorization Cette première idée est une approche plutôt simpliste consistant à définir une certaine plage minimale et maximale dans laquelle les données seront simplement ignorées. Statistiquement, cette marge est définie comme le centile, ce qui signifie la valeur en dessous de laquelle x% des observations dans un groupe vont tomber. Par exemple, 99% des observations de la demande pour un produit seront inférieures à son 99e centile. Cette approche peut être efficace, mais elle peut également entraîner certains problèmes, tels que la détection de faux points aberrants dans un jeu de données sans points aberrants (voir la figure 1 ci-dessous); ou dans le cas de véritables valeurs aberrantes, cela ne réduit pas suffisamment la valeur, ce qui la maintient à un niveau bien supérieur à nos attentes. C’est une approche qui finit par nécessiter une analyse critique très précise de la part du planificateur/prévisionniste; elle n’est donc pas aussi efficace et fiable qu’elle le devrait, car elle supprime les valeurs hautes et basses d’un jeu de données, même si elles ne sont pas exceptionnelles en soi. Figure 1: Winsorization d′un jeu de données simple sans valeur aberrante Détecter les valeurs aberrantes via la méthode de l’écart type Une autre approche consisterait à utiliser la variation de la demande autour de la moyenne historique et à exclure les valeurs exceptionnellement éloignées de cette moyenne, selon un certain intervalle compris entre deux seuils centrés sur la demande . Figure 2: Distance à la moyenne Avec cette méthode, dans une situation sans valeur aberrante, nous ne modifions aucune observation de la demande (nous conservons toutes les valeurs dans ce cas), et dans une autre situation avec une valeur aberrante (voir Y2 ci-dessous), nous ne modifions pas les points de demande faible ou élevée. mais seulement la valeur aberrante réelle (de 100 à 49 dans la figure ci-dessous). Figure 3: Détection des valeurs aberrantes basée sur l′écart type (normalisation) Bien que cela puisse sembler résoudre tous les problèmes découlant de l’approche de WinSorization, la limitation effective se produira lorsque vous aurez un produit avec une tendance ou une saisonnalité. Dans ce cas, sa moyenne historique ne représentera pas avec précision la moyenne réelle pour cette période donnée et, par conséquent, les seuils risquent de ne pas limiter correctement une valeur aberrante possible. Détecter les valeurs aberrantes via l’erreur de l’écart type Pour résoudre les inconvénients de l’écart type et de la Winsorization, revenons à la définition d’une valeur aberrante. Une valeur aberrante est une valeur à laquelle vous ne vous attendiez pas. En d’autres termes, il s’agit d’une valeur éloignée de votre prédiction (c’est à dire votre prévision). Pour repérer les valeurs aberrantes, nous devons donc analyser l’erreur de prévision et voir quelles périodes sont exceptionnellement fausses. Si nous calculons l’erreur de notre prévision, nous obtiendrons une erreur moyenne et un écart-type. Vous pouvez consulter le livre Data Science for Supply Chain Forecast, écrit par Nicolas Vandeput pour voir des exemples de la vie réelle et plus de détails. La figure ci-dessous illustre nos résultats obtenus à partir de nos prévisions. Cette méthode de détection plus intelligente, qui analyse l’écart d’erreur de prévision au lieu de simplement la variation de la demande autour de la moyenne, permet de signaler les points aberrants beaucoup plus précisément et de les ramener à une valeur plausible. Par conséquent, cela devrait être votre méthode préférée pour une prévision précise de la demande. Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT
Gérer la saisonnalité pour une bonne gestion des stocks (lissage exponentiel triple)

Les produits saisonniers sont courants dans de nombreux secteurs et peuvent impliquer un grand nombre de facteurs tels que l’influence des changements climatiques. Par définition, ce sont tous les changements qui influencent constamment votre demande au cours des mêmes périodes. Cela complique quelque peu les modèles de prévision de la demande et limite l’utilisation de certains d’entre eux. Les modèles de prévision à lissage exponentiel simple et lissage exponentiel double (abordés dans les articles précédents) ne reconnaissent pas ces tendances saisonnières et ne peuvent donc pas extrapoler un comportement saisonnier futur. Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT Comprendre le concept afin d’améliorer votre processus de planification de la demande Commençons par récapituler. La prévision (f) dans le lissage exponentiel double est calculée par deux couches, le niveau (a) plus la tendance (b). En insérant la saisonnalité dans le modèle, à l’aide du facteur saisonnier (s), une nouvelle couche de lissage exponentiel est ajoutée. L’estimation est basée sur l’observation la plus récente et son estimation précédente. Un taux d’apprentissage gamma (), est appliqué à la métrique du facteur saisonnier (s). Le modèle utilisera donc une méthode de pondération exponentielle afin de déterminer le pourcentage en poids attribué à l’observation la plus récente par rapport à l’estimation précédente. En d’autres termes, $gamma$ déterminera si la prévision doit répondre rapidement ou non à une certaine variation de la demande. Considérant que la saisonnalité en général n’a pas de changements significatifs d’une année sur l’autre, le maintien d’un taux d’apprentissage faible (par exemple inférieur à 0,3) évitera une adaptation inutile pour s’adapter aux situations exceptionnelles et aux cas particuliers, et fera de cette méthode un modèle de prévision plus régulier. Néanmoins, cela peut nécessiter un certain degré de compréhension de la demande de votre marché, mais savoir si votre saisonnalité est mensuelle, trimestrielle ou annuelle devrait vous donner une bonne idée du meilleur taux d’apprentissage à utiliser. Choisir la bonne méthode pour une prévision précise de la demande saisonnière La technique de lissage exponentiel triple a deux approches différentes et vous devez connaître la nature de votre saisonnalité afin de savoir laquelle utiliser. Le lissage multiplicatif Si vous vendez 20% de plus de votre produit en décembre qu’en novembre, vous avez probablement un caractère saisonnier multiplicatif . Dans ce cas, le ou les facteurs saisonniers sont simplement multipliés dans la prévision: Cette formule prédit avec une précision fiable, répond de manière très efficace aux variations de la saisonnalité et suit la tendance générale de la demande. C’est ce que montre l’exemple ci-dessous qui compare la demande à la prévision. Toutefois, cette méthode peut entraîner des erreurs mathématiques si les volumes ou les facteurs de saisonnalité sont trop proches de 0. Une faible variation de la demande absolue peut également générer une grande différence. Malheureusement, cela signifie que ce modèle ne convient pas à tous les produits et renforce l’importance de connaître le caractère saisonnier de vos produits.Afin de résoudre ce problème, une deuxième approche de prévision de la demande à base de lissage exponentiel triple est préférable: Le lissage additif Si vous vendez 20 000 produits de plus en Décembre qu’en Novembre, alors vous avez un caractère saisonnier de type additif. Avec cette approche, un facteur saisonnier est ajouté au niveau prédit par le modèle de prévision, de sorte que la prévision réponde avec plus d’adhérence, même à de faibles volumes. Maintenant, nous ajoutons le facteur saisonnier (s) dans les prévisions: En mettant les deux approches sur un même graphique, cela nous donne une idée plus claire de la façon dont elles réagiront face à la variation de la demande, montrant ainsi la meilleure adéquation du modèle additif pour le cas ci-dessous. Mais la méthode additive possède aussi ses limites en matière de prévision de la demande, telles que son incapacité à gérer des données externes (budget marketing ou impact des niveaux de prix par exemple). En outre, cette méthode pose un problème pour les articles ayant une tendance significative. La manière dont le modèle de lissage exponentiel triple additif est défini ne permet pas à la saisonnalité d’évoluer rapidement dans le temps, ni d’extrapoler les changements. Ce nouveau modèle additif est en fait le mieux adapté aux articles à demande stable ou à demande faible. Approfondir votre connaissance des méthodes de prévision de la demande pour optimiser votre gestion des stocks Comme vous pouvez le constater, nos deux modèles saisonniers sont complémentaires et devraient vous permettre de prévoir tout produit saisonnier. Cependant, l’obtention de résultats fiables nécessite une compréhension sensible du comportement de la variation de la demande de votre produit au fil du temps. La meilleure façon de savoir lequel vous devez utiliser est bien sûr d’expérimenter, ou de laisser une solution comme SKU Science décider pour vous. Le concept du modèle triple n’est pas si complexe, mais approfondir les équations peut être un peu compliqué sans les outils appropriés. Pour plus d’informations sur ce modèle et d’autres modèles de lissage exponentiel, vous pouvez consulter le livre de référence en ligne, disponible gratuitement, intitulé “Forecasting: Principles and Practice », de Rob J Hyndman et George Athanasopoulos, deux leaders mondiaux dans le domaine de la prévision, et “Data Science for Supply Chain Forecast” par Nicolas Vandeput. SKU Science possède tous ces modèles et outils et peut vous apporter tout le soutien dont vous avez besoin pour appliquer ces méthodes de prévision de la demande de manière fiable et efficace. Ainsi votre processus de planification vous permettra d’améliorer grandement la gestion de vos stocks. Vous pouvez également voir une analyse plus détaillée des deux modèles sur supchains.com Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT
Améliorer la prévision de la demande grâce à la détection de tendance (lissage exponentiel double)
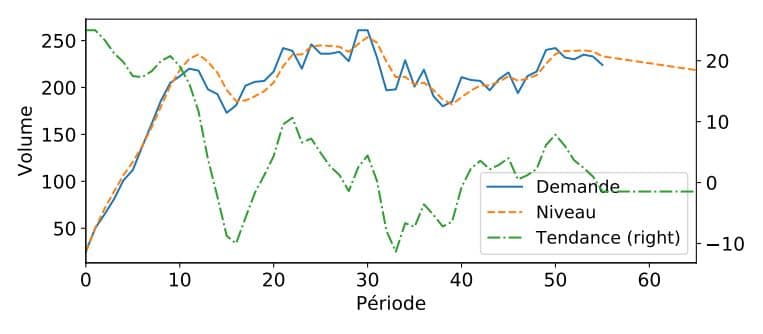
L’exactitude des prévisions de la demande pour le plan industriel et commercial (PIC/S&OP) est extrêmement importante et fondamentale pour son succès au sein d’une entreprise. Certaines lacunes des méthodes de prévision basiques peuvent nuire à la crédibilité de votre PIC. Dans cet article, nous expliquerons comment résoudre certains problèmes associés au modèle de lissage exponentiel simple. Comme indiqué dans un précédent article de blog, ce modèle crée une prévision simple qui suppose que la série chronologique de la demande future est similaire à son passé. Un problème majeur avec ce lissage simple est son incapacité à identifier et à projeter une tendance. Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT Nous définissons la tendance comme la variation moyenne du niveau de série temporelle entre deux périodes consécutives . Dans notre article précédent, nous définissions le niveau comme la valeur moyenne autour de laquelle la demande varie dans le temps. Ainsi, par exemple, si vous aviez un niveau de vente la semaine dernière de 10 pièces et que cette semaine le niveau des ventes est d’environ 20 pièces, cela signifie que vous avez une tendance positive de 10 pièces par semaine. Si vous supposez que votre série chronologique suit une tendance, vous ne connaîtrez probablement pas son amplitude à l’avance; d’autant plus que cette ampleur peut varier dans le temps. Cependant, il existe maintenant un modèle qui permet de distinguer par lui-même la tendance dans le temps. Comme on le voit pour le niveau, ce nouveau modèle estimera la tendance sur la base d’un nouveau paramètre d’apprentissage appelé beta (), donnant plus ou moins d’importance aux observations les plus récentes. Rappelez-vous que alpha () déterminera l’importance accordée à la dernière observation de la demande. Ces techniques de prévision de la demande sont maintenant entièrement disponibles sur SKU Science, et nous expliquons ci-dessous certains de leurs concepts clés. Explications rapides sur la méthode de prévision de la demande à lissage exponentiel double L’idée générale des modèles à lissage exponentiel double est que le niveau et la tendance seront mis à jour à chaque période sur la base de l’observation la plus récente et de l’estimation précédente de chaque composante. Comme vous vous en souviendrez peut-être, avec le modèle de lissage exponentiel simple, nous avons mis à jour les prévisions pour chaque période, en partie en fonction de la demande précédente et en partie en fonction des prévisions précédentes. Nous allons maintenant faire la même chose pour le niveau () et la tendance (). Notre nouveau modèle de prévision de la demande mettra à jour son estimation du niveau à chaque période grâce à deux informations: la dernière observation de la demande et l’estimation du niveau précédent augmentées de la tendance. Ce modèle de prévision de la demande devra également estimer la tendance. Tout comme pour le niveau, elle représente le poids accordé à l’observation de niveau la plus récente. Dès que nous sommes sortis de la période de demande historique, nous prévoyons simplement chaque période comme la dernière prévision plus la tendance. Le modèle extrapolera donc la dernière tendance observée. Cependant, comme nous le verrons plus tard, cela pourrait poser un problème. Vous pouvez voir ci-dessous la représentation mathématique de la technique de prévision: Estimation de niveau: Estimation de tendance: Prévisions futures: Initialisation de notre modèle de prévision de la demande Comme nous l’avons vu avec l’initialisation prévue du lissage exponentiel simple, nous devons examiner comment initialiser les premières estimations de notre niveau et de notre tendance, et nous aurons deux options, décrites ci-dessous. Initialization simple Nous pouvons initialiser le niveau et la tendance simplement en prenant and . C’est une méthode d’initialisation simple et juste. Régression linéaire Une autre façon d’initialiser et serait de faire une régression linéaire des n premières observations de la demande, qui pourrait être définie comme un nombre arbitrairement bas (par exemple 3 ou 5). Nous ne traiterons pas dans cet article de comment faire des régressions linéaires. Compréhension de ces modèles de prévision de la demande Les modèles de lissage exponentiels sont très utiles car ils permettent de comprendre une prévision ou une série chronologique grâce à leur décomposition entre le niveau et la tendance et (comme nous le verrons dans un autre article de ce blog), la saisonnalité . Vous pouvez vérifier l’état de n’importe lequel des sous-composants de la demande à tout moment, tout comme vous pourriez vérifier ce qui se passe sous le capot d’une voiture. il n’en va pas de même avec un algorithme à base d’intelligence artificielle. Dans l’exemple ci-dessous, nous avons tracé ces différents composants pour vous montrer comment notre modèle interprète l’évolution de la courbe de demande d’un produit. Nous sommes ainsi capable d’expliquer la valeur de chaque point de prévision. La valeur des différents paramètres de lissage vous indiquera également quelque chose sur la variabilité ou la régularité de votre produit. Les valeurs élevées désigneront un produit où chaque variation devrait avoir un impact sur les prévisions; les valeurs faibles désigneront des produits ayant un comportement plus constant et qui ne devraient pas être affectés par des fluctuations à court terme. Limites du modèle de prévision de la demande à lissage exponentiel double Notre modèle à lissage exponentiel double est maintenant capable de reconnaître une tendance et de l’extrapoler dans le futur. C’est une amélioration majeure par rapport au lissage exponentiel simple ou à la moyenne mobile. Malheureusement, cela comporte un risque. Notre modèle suppose que la tendance se poursuivra éternellement. Cela pourrait entraîner des problèmes pour les prévisions à moyen / long terme. Nous allons résoudre ce problème grâce au modèle de tendance amorti, un modèle publié il y a 25 ans, en 1985! Outre le risque de tendance infinie, nous avons encore Le manque de saisonnalité. Ce problème sera résolu via le modèle de lissage triple exponentiel détaillé dans notre prochain article de blog. L’impossibilité de prendre en compte des informations externes (telles que le budget marketing ou les variations
Comprendre les modèles de prévision de la demande pour améliorer la gestion des stocks
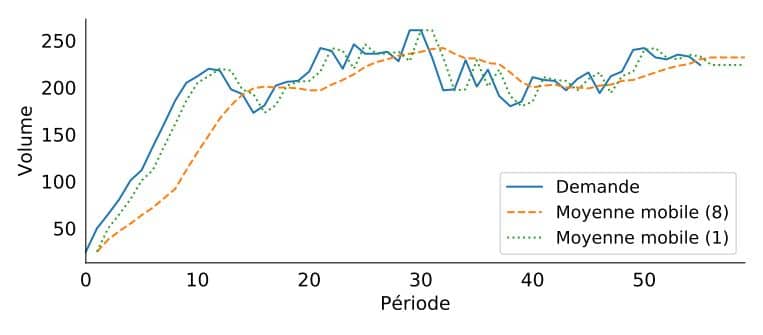
La prévision de la demande future constitue la base de toutes les décisions stratégiques et de planification dans une chaîne d’approvisionnement. Une entreprise définit ses efforts en fonction de l’orientation de son activité, qui peut être déterminée en l’appuyant sur une méthode appropriée de prévision de la demande. De plus, celle ci est à la base d’un processus de planification industrielle et commerciale (PIC) couvrant la production, les ventes, le marketing et les domaines de la finance, pour permettre aux gestionnaires de diriger correctement et aligner leurs actions sur des données plutôt que fondées sur des hypothèses individuelles. Essayez notre solution de prévision simple et rapide ! Inscrivez-vous aujourd’hui gratuitement sur SKU Science Données d’échantillon rechargées – Aucune carte de crédit requise INSCRIVEZ-VOUS GRATUITEMENT Pour réussir à suivre cette approche et garantir des résultats fiables, les responsables doivent prendre des décisions importantes concernant les prévisions et le type de technique de prévision de la demande. Différentes techniques sont disponibles, mais avec des différences substantielles entre elles qu’il convient de choisir en tenant compte de plusieurs facteurs. La plupart des techniques étant quantitatives , ces facteurs doivent inclure le niveau de complexité des produits ou du marché, la maturité des processus de la chaîne d’approvisionnement de l’entreprise et la disponibilité de données fiables.Plusieurs techniques de prévision de la demande de base bien connues, pouvant servir de point de départ, utilisent des données historiques pour prédire l’avenir, mais avec quelques différences qui seront expliquées ci-dessous et dans les articles suivants. Le modèle de prévision de la moyenne mobile Le premier et le plus élémentaire est le modèle de moyenne mobile, une méthode de prévision de la demande basée sur l’idée que la demande future est similaire à la demande récente observée. Dans ce modèle, on suppose simplement que la prévision est la moyenne de la demande au cours des n dernières périodes. Si vous regardez la demande sur une base mensuelle, cela pourrait se traduire par «Nous prévoyons que la demande en juin sera la moyenne de mars, avril et mai». L’une des conditions de base du modèle est de commencer à créer une base de données historique, car vous ne disposerez pas de prévisions avant que suffisamment d’observations de la demande aient été collectées. Une fois sorti de la période historique, vous définissez simplement les prévisions futures comme les dernières faites sur la base de la demande historique. Cela signifie qu’avec ce modèle, la prévision de la demande future sera stable. Par conséquent, l’une des principales restrictions de ce modèle sera son incapacité à extrapoler les tendances. Modèle de prévision de la demande de lissage exponentiel En ce qui concerne la moyenne mobile, on suppose que l’avenir sera plus ou moins le même que le passé. De même, le modèle de lissage exponentiel sera capable d’apprendre le niveau à partir de l’historique de la demande. Le niveau est la valeur moyenne autour de laquelle la demande varie dans le temps. Il est important de comprendre qu’il n’existe pas de définition mathématique définitive du niveau; à la place, il appartient à notre modèle de l’estimer. Comme vous pouvez le constater, le modèle de lissage exponentiel prévoira ensuite les demandes futures en tant que dernière estimation du niveau. L’idée de base de tout modèle de lissage exponentiel est que, à chaque période, le modèle apprendra un peu à partir de l’observation de la demande la plus récente et se rappellera un peu de la dernière prévision établie. La magie à ce sujet est que la dernière prévision du modèle comprend une partie de l’observation de la demande précédente et une partie de la prévision précédente. Et ainsi de suite. Par conséquent, cette prévision précédente inclut en réalité tout ce que le modèle a appris jusqu’à présent, en fonction de l’historique de la demande. Le paramètre de lissage (ou taux d’apprentissage) alpha () déterminera quelle importance est accordée à l’observation de la demande la plus récente. Représentons ceci mathématiquement: représente l’observation de la demande précédente multipliée par le taux d’apprentissage. représente la manière dont le modèle se souvient de sa prévision précédente. Sur la figure ci-dessous, nous voyons qu’une prévision faite avec une valeur alpha basse (ici 0,1) mettra plus de temps à réagir à une demande changeante, tandis qu’une prévision ayant une valeur alpha élevée (ici 0,8) suivra de près les fluctuations de la demande. Vous pouvez trouver plus d’informations sur ce modèle sur supchains.com Un modèle de prévision de la demande avantageux et un point de départ important Il convient de souligner deux avantages clés sur le lissage exponentiel: • Le poids associé à chaque observation diminue de manière exponentielle avec le temps (l’observation la plus récente a le poids le plus élevé). • Nous pouvons réduire l’impact des valeurs aberrantes et du bruit grâce à alpha (α), le poids exponentiel. Comme expliqué dans le livre “Data Science for Supply Chain Forecast” écrit par Nicolas Vandeput, un compromis important doit être fait entre apprendre et se souvenir; entre être réactif et être stable. Si le taux d’apprentissage est élevé, le modèle accordera une plus grande importance à l’observation de la demande la plus récente et sera réactif à une modification du niveau de la demande. Mais il sera également sensible aux valeurs aberrantes et au bruit. D’autre part, si le taux d’apprentissage est faible, le modèle ne remarquera pas de changement de niveau rapidement, mais ne réagira pas de manière excessive avec le bruit et les valeurs aberrantes.Mais il faut aussi prendre en compte certaines contraintes de planification de la demande: • Le modèle de lissage exponentiel ne projette pas de tendances et ne reconnaît aucun schéma saisonnier.• Il ne peut utiliser aucune information externe (telle que les prix ou les frais de marketing). Réflexions finales sur le choix d’une méthode de prévision de la demande pour améliorer la gestion des stocks Ce premier modèle de lissage exponentiel sera probablement trop simple pour obtenir de bons résultats, mais il constitue une bonne base pour la création ultérieure de modèles plus complexes.